
January 15th, 2021



前提
學習 Raft 的演算法的時通常都會將 Byzantine Failure 給排除掉,想不到在去年十一月底的 CloudFlare 的 incendent report 竟然用了現實世界的拜占庭問題來當作標題,就用這個來整理一些思緒。
什麼叫 Byzantine failure
在分散式系統中,不同電腦之間會相互的溝通作為「Consensus Communication」的資料確認流程。 需要不同電腦間,回報自己將要做的事情,或是進行 leader 投票的流程。 如果這時候發生了有一台電腦,跟某些團員講 A 跟另外一群團員又講 B 的狀況,造成整個團體無法達成一制性,或是達成了非預期狀態,就被稱為是 Byzantine Failure 。 許多的狀況下, Consensus Algorithm 舉凡 Paxos 跟 Raft 都會先假設 Byzantine Failure 是不存在的,因為這個問題會將 Consensus 複雜度又提升到另外一個境界。
參考文章:
關於 CloudFlare 的復原機制
探討比較複雜的問題之前,其實這篇文章還有一個有趣的角度可以觀察。 就是如何透過 CloudFlare 的 Incident Report 來查看他們針對系統維護上有那一些備援機制。
服務備援機制
- 每一個服務都是一系列的 Rack Servers
- 每台機器有兩個 switches
- 每個機器主機架有兩個以上的電源供應設備
- 每個 server 都使用 RAID-10 的備份機制 (也就是 RAID 1 + RAID 0 的備份機制)
- 每一個 Rack 至少都是三台機器以上。
發生的問題
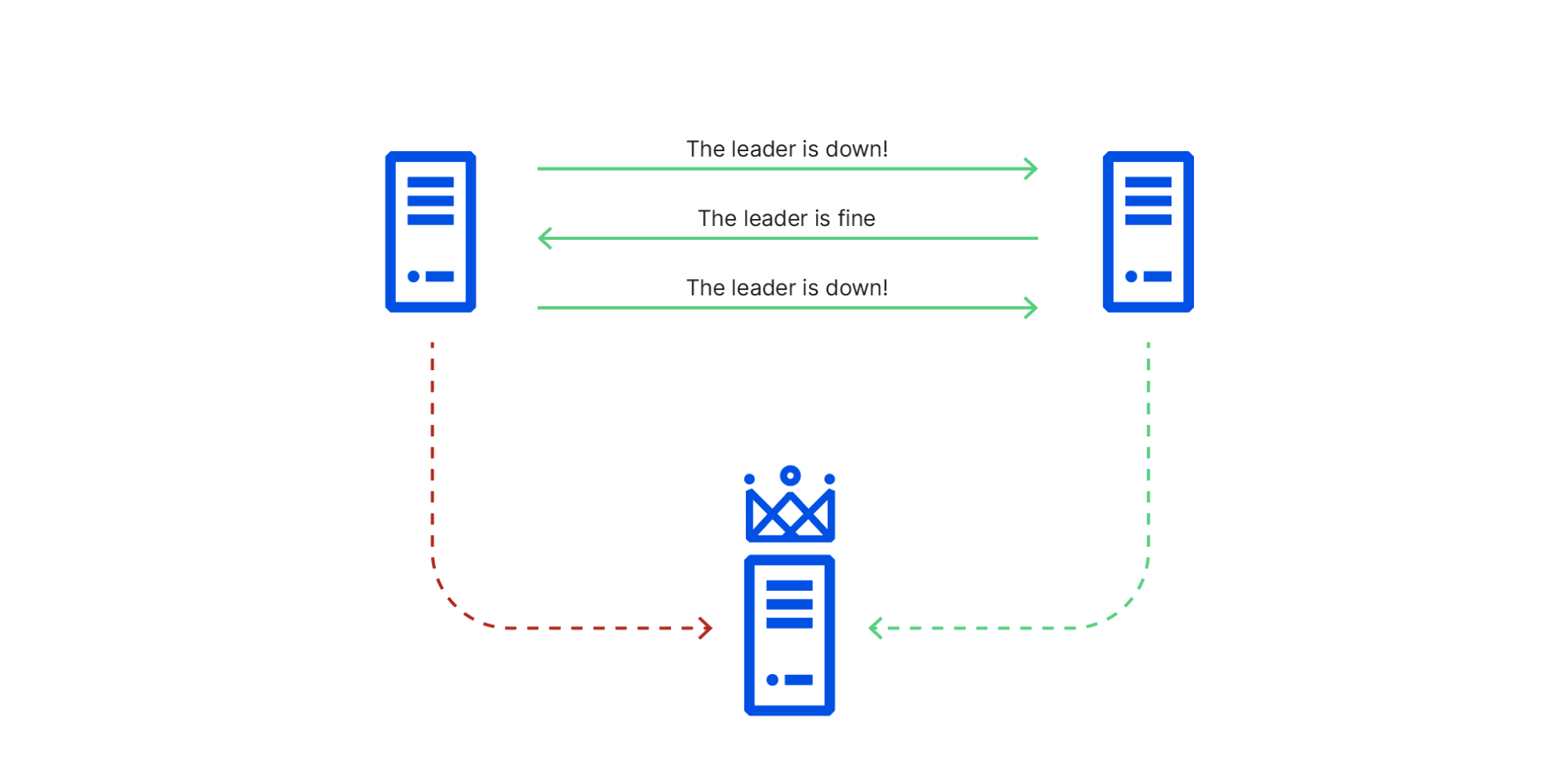
(圖片解釋: 左上角為 Server 1, 右側為 Server 2,下方為 Server 3 也是 Leader )
- 由於 Server 1 到 Server 2 的網路發生問題。
- 造成 Server 1 與 Server 2 發生不同步的資訊問題。
- Server1 認為 Leader (Server 3) 已經下線
- Server 2 認為 Leader 是正常運行。
- 也是因為這樣的原因, CloudFlare 將這個問題在為 Byzantine Failure
Reference
-
Raft does not Guarantee Liveness in the face of Network Faults
- Raft lecture (Raft user study) by Diego Ongaro
- The Cloudflare Blog
- Improving the Resiliency of Our Infrastructure DNS Zone
- A Byzantine failure in the real world
- Link aggregation - Wikipedia
- Cloudflare Status - Cloudflare Dashboard and Cloudflare API service issues
- Raft does not Guarantee Liveness in the face of Network Faults
-
[Understanding the Byzantine Generals’ Problem (and how it affects you) by Anthony Stevens Coinmonks Medium ](https://medium.com/coinmonks/a-note-from-anthony-if-you-havent-already-please-read-the-article-gaining-clarity-on-key-787989107969) - Raft Consensus Algorithm