
關於 Bloom Filter
應用場景
處理大型資料的時候,往往需要一個索引可以快速的找到資料.這樣的索引就被成為 filter.
針對要搜尋一個數字的位址或是是否存在,簡單的方式就是每一個都找過一次,這樣下去的時間複雜度就是 \(O(n)\) .
也有一個比較快的方式就是將所有的數字變成一個陣列,然後該數字存在就將其紀錄為 “1” 的 (Mapping Table) 方式,這樣的時間複雜度就會優化為 \(O(1)\) 但是空間複雜度就會變成了 \(n\) .
那麼是否有一個資料結構能夠兼具 \(O(1)\) 的時間複雜度,但是又不需要有 \(n\) 的空間複雜度的 Filter 呢?
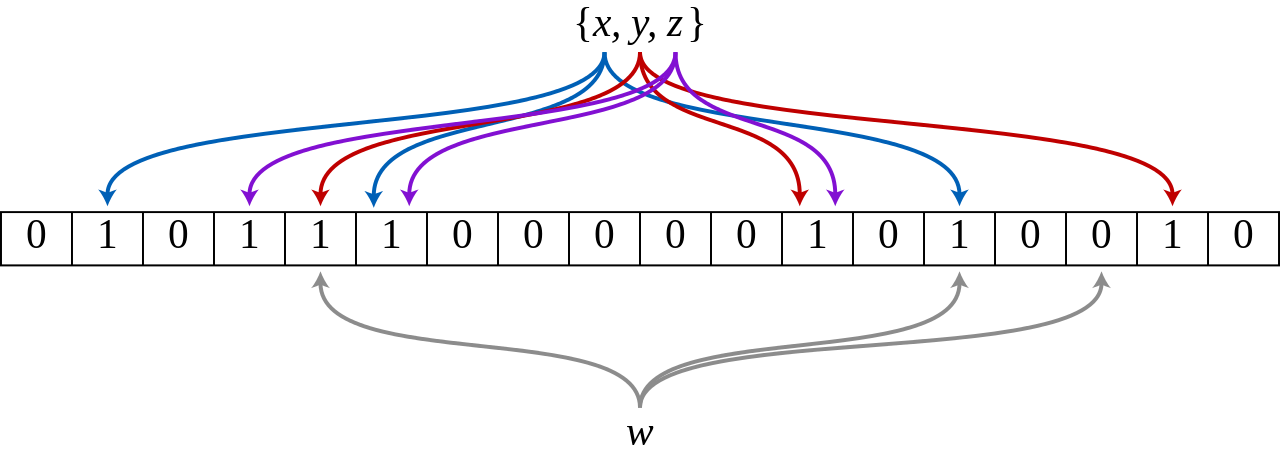
Bloom Filter 是一個 Hashing table 提供你快速的搜尋 ( \(O(1)\) ) 的資料結構. Bloom Filter 運作方式如下:
- 每一個資料會透過 Hash Function 後存在某個 Array 位置裡面
- 只存放 (1: 存在, 0:不存在) 兩種資料
Bloom Filter 實作的細節:
實作 Bloom Filter 有一些細節需要去取捨:
- False Positive 的機率 (\(p\))
- 需要幾個 Filter 來表示全部的資料 (\(n\))
- 每個 Filter 需要多少資料欄位 (\(m\))
- 需要幾層的 Hash Function (\(k\))
在預先設定的 \(p\) 機率與給定希望的 filter size \(n\) 下, 我們可以計算出所需要的資料欄位 \(n\) 與 幾層 Hash Function \(k\).
而計算式子如下,其實代碼裡面都有:
\[m = -1 * (n * lnP)/(ln2)^ 2\] \[k = m/n * ln2\]可以參考這個網頁
Bloom Filter 優點:
- 快速地查詢時間 O(1)
- (不要想說,資料庫更快.因為很多資料庫都是透過 Bloom Filter 來做為查詢 (ex: Cassandra Partition Query ))
- 索引資料結構小 (只有一個 bit 0:1)
Bloom Filter 缺點(限制):
但是這樣快速的資料結構其實有它先天上的限制:
- 只能回答你絕對不在,但是無法確認該物件一定在.會有誤判 (false positive) 的可能. (但是不會有 False Negtive)
- 資料節點,只能夠新增進去無法刪除.
補充: 一張很容易了解 (False Positive, False Negtive, True Positive, True Negtive )
Bloom Filter 應用場景 - Cassandra Partition Cache
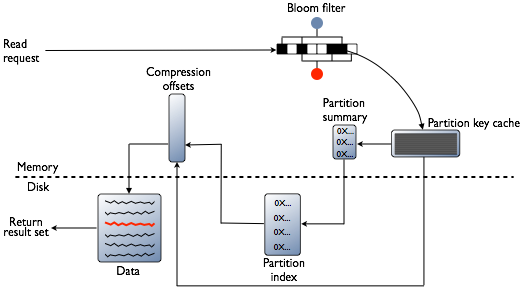
或許大家會思考,要找一個資料在不在某個地方.不是直接去找資料庫就好了嗎? 其實,在 Cassandra 裡面就有利用到 Bloom Filter 來決定該資料是否存在某個 Partition
透過 Bloom Filter 可以快速知道資料是否放在 Partition Key Cache ,如果不在就要再透過資料直接去 Partition Index 尋找資料.
Ref: Datastax About Read
Bloom Filter 改良版 Counting Filter

Bloom Filter 有著不能刪除新資料的限制,因為你把原先為 1 的改成 0的時候,你不知道原先有多少個節點是對應該該位置.後來在資料欄位上新增了計數器 (counting) 就能夠解決不能刪除節點的問題.
透過新增計數單位可以記錄總共有幾個點是透過 Hashing Function Mapping 到該節點上面.到時候要刪除的時候也就可以確認是否所有對應到該節點的個數都有確切地被刪除.
運作方式為:
- 新增一個節點進( CBF: Counting Bloom Filter ) 就將該 Hashing 過的位置裡面數值加一
- 要刪除節點的時候就會把該數值減一.
Counting Bloom Filter 的缺點
為了要解決不能刪除節點而加入的計數欄位,就會變成讓資料量反而又變大了.
程式碼:
多說無益,來看程式碼
Reference

